1. 사용 이유
1) Numpy array의 한계
- 가독성이 떨어짐
- 정보에 대한 레이블 삽입 불가
- 한 가지 데이터 타입만 사용 가능
2) Pandas로 가능한 작업
- 데이터 불러오기
- 데이터 가공
- 데이터 분석
- 데이터 시각화
3) Numpy vs Pandas
- Numpy: 복잡한 수학 연산을 할 때
- Pandas: 표 형태의 데이터를 간편하게 다루고 싶을 때
2. Pandas 축약형
import pandas as pd
3. 형식
#데이터프레임 표형식
df = pd.DataFrame(#dictionary 삽입)
#예시
df = pd.DataFrame({
'category': ['skirt', 'sweater', 'coat', 'jeans'], #카테고리 목록의 리스트
'quantity': [10, 15, 6, 11], #수량 리스트
'price': [30000, 60000, 95000, 35000] #가격목록 리스트
})
df
#df라는 변수에 괄호 안 내용의 파라미터를 저장해준 것 !
#변수 이름은 자유롭게 입력 가능
#표의 가로축을 컬럼이라고 하며, 세로를 로우라고 함.
#가로에는 주로 리스트가, 세로에는 인덱스가 옴 !
4. 데이터 가져오기
#특정 데이터값만 불러 오는 건 Numpy랑 비슷함
#Pandas는 Numpy를 바탕으로 만들어졌기 때문
#예시
df = pd.DataFrame({
'category': ['skirt', 'sweater', 'coat', 'jeans'],
'quantity': [10, 15, 6, 11],
'price': [30000, 60000, 95000, 35000]
})
#quantity만 가져오려면?
df['quantity']
#이 때 type(df['quantity'])를 해보면 더 이상 Dataframe이 아닌 Series로 변함.
#데이터는 2차원식, Series는 1차원식
5. 평균/최소/최대 등을 구하는 방법
#수량의 평균, 합계, 최소값 등 계산하기
df['quantity'].mean() #mean이 평균을 의미
df['quantity'].sum() #합계
df['quantity'].min() #최소값
#예시: 항목별 총 가격 계산 방법
df['quantity'] * df['price']
#예시 최대 골 수 개산하기
goals_max = players_df['goals'].max() #goals라는 컬럼을 선택해 거기서 최대값을 뽑아냄
print(goals_max)
6. DataFrame을 만드는 다양한 방법
#pd.DataFrame()안에 DataFrame으로 만들 재료는 꼭 dictionary만 있는 건 아님
#리스트나 NumPy array를 넣을 수도 있음
#1. 딕셔너리 사용
dict_df = pd.DataFrame({
'category': ['skirt', 'sweater', 'coat', 'jeans'],
'quantity': [10, 15, 6, 11],
'price': [30000, 60000, 95000, 35000]
})
#2. 2차원 리스트(two_dimensional_list)와 2차원 NumPy array(two_dimensional_array) 사용
two_dimensional_list = [
['skirt', 10, 30000],
['sweater', 15, 60000],
['coat', 6, 95000],
['jeans', 11, 35000]
]
two_dimensional_array = np.array(two_dimensional_list)
list_df = pd.DataFrame(two_dimensional_list)
array_df = pd.DataFrame(two_dimensional_array)
#이렇게 만든 데이터프레임은 만들 때 컬럼의 이름을 따로 설정하지 않았기 때문에 따로 추가로 컬럼명 설정 필요
list_df = pd.DataFrame(two_dimensional_list, columns=['category', 'quantity', 'price'])
array_df = pd.DataFrame(two_dimensional_array, columns=['category', 'quantity', 'price'])
#위의 컬럼명을 제일 처음 추가해줘야함.
#3. 딕셔너리가 담겨 있는 리스트 사용
dict_list = [
{'category': 'skirt', 'quantity': 10, 'price': 30000},
{'category': 'sweater', 'quantity': 15, 'price': 60000},
{'category': 'coat', 'quantity': 6, 'price': 95000},
{'category': 'jeans', 'quantity': 11, 'price': 35000}
]
dict_list_df = pd.DataFrame(dict_list)
7. 데이터 불러오기
*CSV 파일(컬럼으로 구분되어 있는 파일)
1) 헤더 O
- 첫쨋줄: 상품명, 칼로리, 단백질, 지방
- 둘쨋줄: 와퍼, 600, 35, 10
- 셋쨋줄: 감튀, 500, 10, 30
- 넷쨋줄: 치즈스틱, 300, 5, 40
2) 헤더 X
- 첫쨋줄: 와퍼, 600, 35, 10
- 둘쨋줄: 감튀, 500, 10, 30
- 셋쨋줄: 치즈스틱, 300, 5, 40
#pd.read_#파일종류("#파일경로")
#예시
#1. 헤더가 있는 CSV 파일
pd.read_CSV("data/burger.csv") #CSV파일을 #data폴더의 buger라는 제목의 파일명을 불러 옴
#CSV 파일 중 헤더가 있는 파일인 경우 컬럼이 자동으로 생성됨
#2. 헤더가 없는 CSV파일
#header=None을 추가로 적어줘야 컬럼이 제멋대로 생기는 걸 방지 가능
pd.read_CSV("data/burger.csv", header=None)
#3. 헤더가 없는 CSV파일에 컬럼명 추가하기
pd.read_CSV("data/burger.csv", header=None,
names=["product_name","calories", "carb", "protein"])
#실제 컬럼의 갯수랑 names안의 리스트의 갯수랑 동일해야함
#4. CSV파일에 로우명(인덱스) 추가하기
pd.read_csv("data/burger.csv", index_col="product_name")
#인덱스 컬럼 중 product_name을 로우명에 추가한 것 !
#인덱스 컬럼은 절대로 다른 인덱스 내용과 겹치면 안됨
#만약 가장 왼쪽의 컬럼을 로우명으로 추가하고 싶으면 index_col=0이라고 적으면 됨
#두 번째 컬럼은 index_col=1 ...
8. DataFrame에서 일부만 선택하는 법
1) loc(location) vs iloc(integer location)
- 컬럼 이름이나 로우 이름을 통해서 데이터를 받아옴 vs 파이썬이나 넘파이에서 하던 인덱싱이라 유사
#1.iloc
df.iloc[로우, 컬럼]
df.iloc[[로우1, 로우2], [컬럼1, 컬럼2]] #여러 값 가져오기
df.iloc[1:4, :3] #슬라이싱 #1~3로우값, ~2 컬럼 값
#2.loc
buger_df.loc['double whopper', 'protein'] #각 로우에서 원하는 값, 각 컬럼에서 원하는 값
buger_df.loc['double whopper', 'whopper'] , 'protein', 'carb', 'fat'] #여러 값 가져오기
buger_df.loc['double whopper':'bacon king', 'calories':'fat'] #슬라이싱 #iloc과 다르게 마지막 값도 포함됨
#3.iloc과 loc 둘다 안 쓰는 경우(그냥 컬럼만 받아 올 경우)
buger_df['calories'] #칼로리 컬럼을 통째로 받아 올 수 있음
buger_df['calories', 'fat'] #여러 개 컬럼 통째로 받아 올 수 있음
buger_df['double whopper':'bacon king'] #loc이나 iloc을 안 쓸 경우 슬라이싱은 컬럼이 아닌 로우에 대해서만 가능함
9. DataFrame과 불린 인덱싱
buger_df['calories'] < 500 #칼로리 500 이하면 T로 나옴 !
#로우 필터링 #마스킹 = 필터링 하기
buger_df.loc[buger_df['calories'] < 500] T인 값만 필터링해서 나옴
#컬럼 필터링
buger_df.loc[buger_df['calories'] < 500, 'protein'] 로우 중 T인 값과 프로틴 컬럼에 해당하는 값만 출력
buger_df.loc[buger_df['calories'] < 500, ['protein', 'carb']] #여러 컬럼값 추출
buger_df.loc[buger_df['calories'] < 500, 'protein':'fat'] #슬라이싱도 가능 !
#로우 필터링이 필요 없이, 특정 컬럼만 필터링하고 싶으면 loc이 굳이 필요 없음
buger_df[buger_df['calories'] < 500]
#좀 길어진다 싶으면 mask 활용 가능
mask = buger_df['calories'] < 500
buger_df[mask]
#mask 활용2
mask = buger_df['calories'] < 500
buger_df.loc[mask, 'calorories':'fat'] #칼로리 500에 해당하는 로우와 칼럼은 칼로리~지방까지
10. 데이터 수정하는 법
#1.값을 하나씩 바꿔주는 법
#수정하고 싶은 값의 위치를 입력해준 다음 = 수정하고 싶은 값
buger_df.loc['Double Stacker King', 'Sodium'] ] = 1.9
#2. 로우 한줄 통째로 수정
#치즈버거 로우(5줄)을 전부 수정할 경우
buger_df.loc['cheesebuger'] = [360, 24, 18, 21, 0.7] #리스트 값도 5칸으로 맞춰줘야함
#컬럼 바꿀 때도 같음 !
#3. 한 컬럼에 해당하는 모든 값을 전부 같은 값으로 변경할 경우
buger_df.loc['sodium']=1
11. 데이터 추가하는 법
#1. 새로운 로우 추가하는 법(제일 끝에)
buger_df.loc['Tripple whopper'] = [1130, 49, 67, 75, 1.1]
#즉 트리플와퍼(칼로리 1130, 칼슘 49,...)에 해당하는 값을 추가해준 것 !
#2. 새로운 컬럼 추가하는 법
buger_df['brand'] = 'Buger King'
buger_df
#브랜드 컬럼을 추가한 거고 그 하위 값은 전부 버거킹
#3. 특정 값만 찾아서 추가 표기하는 법
#ex. 칼로리 500이상인 햄버거만 고칼로리라고 표시하기
#buger_df.loc[buger_df['calories'] >=500] =>마스킹(필터링)먼저 해주고
buger_df.loc[buger_df['calories'] >=500, 'high_calorie'] = True
buger_df.loc[buger_df['calories'] < 500, 'high_calorie'] = False
#high_calorie라는 새로운 컬럼을 추가하고 이상이면 T 미만이면 F 라고 나오도록 하기
12. 그래프 그리기
1) 방법1
- 꼭 Numpy Array를 넣을 필요 없이 Pandas Series를 넣어줄 수도 있음
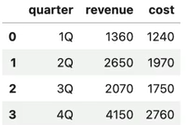
- 이 표를 바탕으로 가로축이 분기 세로축이 수익인 선 그래프를 그린다고 가정
plt.plot(sales_df['quater'], sales_df['revenue'])
plt.show
2) 방법2
- Pandas만의 간단한 방법 !
sales_df.plot()
plt.show- Data Frame에 있는 정보만으로 Pandas가 유츄해서 만들어 줌 !
3) 방법3
- 방법2에서 x축과 y축 지정도 가능
sales_df.plot(x=quater, y=revenue)
plt.show
4) 방법4
- 방법3에서 그래프 종류까지 지정
- 막대그래프 만들기
sales_df.plot(x = 'quater', y = 'revenue', kind ] 'bar')
plt.show
5) 방법5
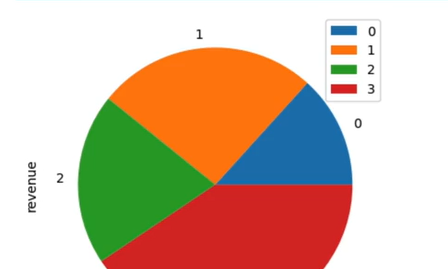
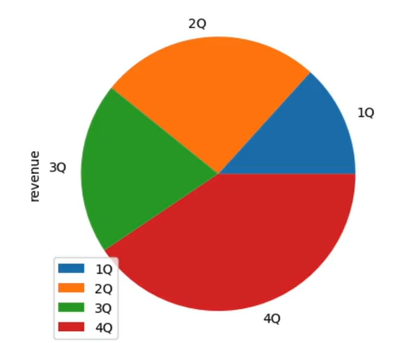
- 방법 4에서 각각 해당하는 값에 레이블을 붙여주기
- 파이그래프라 가정했을 경우
sales_df.plot(y='revenue', kind='pie', lables=['1Q', '2Q', '3Q', '4Q'])
plt.show
'데이터분석 공부 > 03. 데이터사이언스 Toolkit' 카테고리의 다른 글
| 03. matplotlib (4) | 2025.02.20 |
|---|